Piksel services provide a RESTful API allowing clients to interact with the service using standards widely applied across the World Wide Web, namely HTTP, URI and Media Types. A basic familiarity with REST and RESTful APIs is assumed.
Keywords
The key words “MUST”, “MUST NOT”, “REQUIRED”, “SHALL”, “SHALL NOT”, “SHOULD”, “SHOULD NOT”, “RECOMMENDED”, “MAY”, and “OPTIONAL” in this document are to be interpreted as described in RFC 2119 [RFC2119].
URI
Format
Uniform Resource Identifier (URI) is specified as having the following format (using ABNF):
scheme "://" authority "/" path ["?" query] ["#" fragment]
URIs are used in both URN form for name identifiers and URL form for locators.
URI Template is used to describe variable parts of a URI.
Identifiers
Piksel services make use of URNs for canonical identifiers of the form:
urn:piksel:{service}:{resource}:any
urn:piksel:{service}:{resource}:{tenant}:{name}
Where:
pikselis the literal indicating that the urn is of the piksel format{service}is the unique service publicId in short form{resource}is the unique resource name, in plural formanyis the literal indicating any instance of the resource for the given account{tenant}is the unique tenant name, conforming to the name type{name}is the specific value for the unique name for the given resource for the given tenant, conforming to the name type
In many cases, the {tenant}:{name} pairing is sufficient and this is known as a ref.
Example canonical forms:
urn:piksel:identity:tenants:anyurn:piksel:identity:tenants:root:root
Example ref forms:
root:root
Locators
Piksel services makes use of all parts of the URI format for locators (i.e. URLs).
Scheme
HTTP
All piksel services support HTTP and/or HTTPS schemes, depending on the security needs of the resources.
For example:
- All identity service interaction will be over HTTPS
- All persistent resources data service interaction will be over HTTPS
- All service health checks will be over HTTP
Accessing a resource using the incorrect scheme (i.e. other than HTTP or HTTPS) will result in a 404 Not Found response. Where HTTPS is mandated, HTTP traffic will be redirected to HTTPS.
Resourceful
resourceful: is an alternative scheme which provides an abstraction of service locations and is resolved to HTTP/HTTPS URLs by the Registry service. For more details, see Resourceful URI Scheme
Authority
The authority is used to denote the service responsible for handling the request.
HTTP
Each service in each environment will have a different authority, for example:
identity-euw1shared.pikselpalette.comfor the EU production identity serviceidentity-use1shared.pikselpalette.comfor the US production identity serviceidentity-integration.pikselpalette.comfor the integration identity service
Path
The path may consist of many segments. It is the least specific part of the format.
For example, in data services, the path typically follows the following format:
/data/{resource}/{?ref}/?*
Where:
datais the path prefix for data endpoints{resource}is the unique resource name, in plural form{?ref}is the optional ref identifier?*are further path parts specific to the endpoint
The precise format of path for a given resource is documented on a per service basis.
Query
The usage of the query part of the URI format is specific to the HTTP method and endpoint. See later in the guide for more details.
Examples
Some examples of URLs for piksel services
https://identity-euw1shared.pikselpalette.com/oauth/tokenhttps://task-euw1shared.pikselpalette.com/data/jobs/test%3Aexample
Note that : in a ref has to be encoded in percent form to %3A.
HTTP
Semantics
The semantics of HTTP are covered in detail in the Hypertext Transfer Protocol (HTTP/1.1): Semantics and Content draft specification. HTTP method semantics are particularly important as it is the primary source of request semantics, indicating the purpose for which the client has made the request and what is expected by the client as a successful result.
A method must have the same semantics when applied to any resource, though each resource determines for itself whether those semantics are allowed and how they are implemented.
Method Properties
The following method properties are notable:
- safe - methods are considered safe if their semantics are that they do not change any state on the server, although it may cause behaviour such as logging, usage etc. GET, HEAD, OPTIONS and TRACE are safe methods.
- idempotent - methods are considered idemptotent if their semantics are that multiple identical requests have the same net effect as a single such request. PUT and DELETE are idempotent methods.
- cacheable - methods are considered cacheable if their responses are allowed to be stored for future reuse. GET and HEAD are cacheable methods.
Security
All authenticated interaction MUST be over HTTPS and any non-authenticated interaction MAY be over HTTP.
Caching
Servers MAY use HTTP caching headers (ETag, Last-Modified) in accordance with the semantics described in HTTP 1.1.
Conventions
Routes
The following table and diagram map piksel service routes (i.e. methods and path combinations) to operations in line with standard REST semantics.
| Method | Path | Operation | Description |
|---|---|---|---|
| GET | /resources | browse | Fetches a list of resources that may be filtered |
| GET | /resources/{id} | get | Fetches one or more resources using the supplied id(s) |
| POST | /resources | store | Stores one or more resource(s), either creating or wholly replacing |
| PUT | /resources/{id} | store | Stores the supplied resource with the supplied id, either creating or wholly replacing |
| DELETE | /resources/{id} | delete | Delete the resource having the supplied id(s) |
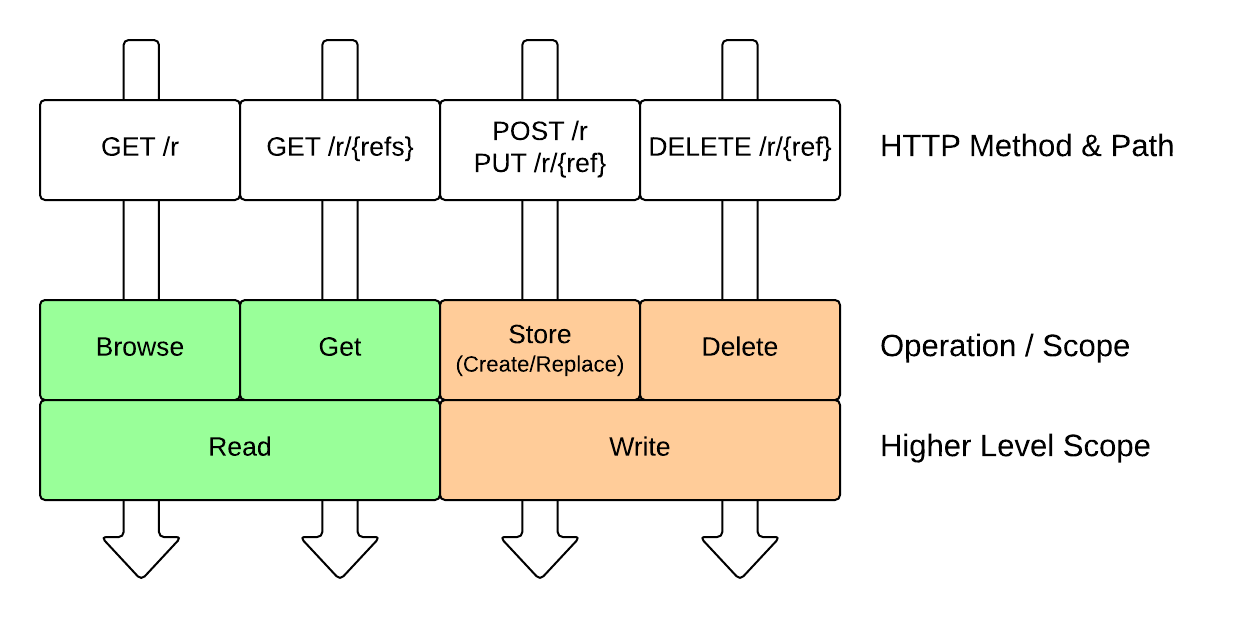
The above operations can be grouped into read and write operations.
- read - operations that do not change state (safe), e.g. list, get
- write - operations that change state (unsafe), e.g. store, replace, delete
Ownership
All resources are owned by a tenant. There is a special top level tenant called root that
is the owner of all root objects including itself.
Tenants have a list of features that are enabled based on customer contracts. Access is granted to a particular tenancy through role based assignments either to a user or the directory through which a user authenticated.
The ?owner= query string parameter should be used to limit the scope of a request to a
specific tenant. For example:
GET /data/users?owner=test
DELETE /data/users/test:user1?owner=test
On browse or get requests it limits the response to resources owned by the tenant.
On storeBatch, storeOne and delete requests, only resources owned by the tenant
will be created, modified or deleted. Write requests that affect resources owned by a
different tenant to the one passed will respond with 403 Forbidden.
When to pass the owner param
In general it is best practice to always pass an owner in requests. However, there are some situations where you might need to pass an owner, and some where it makes sense not to.
It depends on the type of role assignment the authenticated user has. There are two
types of role assignment, static and dynamic.
staticassignments specify aroleRef,tenantRefand either auserRefordirectoryRef. For example, it might grant user1 the user-management role in thetesttenant.dynamicassignments don’t specify atenantRef. Instead they are granted access to all tenants. However, they can only operate on one tenant per request, and the tenant must be specified.
In both cases, the level of access they have is determined by taking the intersection of the tenants feature actions and the role actions.
Additional static assignments can be created that grant users access to several tenants at
the same time. In this situation, it is possible to operate across multiple tenants by
not passing the owner query parameter. Note this also works for dynamically assigned
users who have additional static assignments.
Typically endusers, editors, and tenant admins are given static assignments. Dynamic assignments are used for system and service clients which operate across tenants, either on behalf of users or for internal operations. Sysadmins are also usually dynamically assigned.
Information
The following provides guidance as to the most suitable placement for information in a request:
- The location of a resource is determined by the URI scheme, authority and path. Avoid using query parameters.
- The action to take on the located resource is determined by the semantics of the HTTP method.
- The handling of the request, such as state and content negotiation, is determined by the HTTP headers & cookies.
- The representation is provided in the HTTP entity-body (i.e. payload)
- Any filtering of the resource or representation is determined by URI query parameters.
Media Type
In order to meet the RESTful interface constraint, Piksel APIs will use vnd.piksel+json media type. Piksel API
documents are defined in JavaScript Object Notation (JSON) [RFC4627].
Although the same media type is used for both request and response documents, certain aspects are only applicable to one or the other. These differences are called out below.
Character Encoding
The default character encoding for vnd.piksel+json is UTF-8. Whilst other charsets can be sent and received,
support for them is specific to a given implementation rather than mandated as part of the API.
Profile Link Header
Every vnd.piksel+json API response MUST contain a profile link header to this guide. For example:
Link: <http://developer.pikselpalette.com/concepts/api/spec.html>;rel="profile"
Top Level
A JSON object MUST be at the root of every Piksel API document. This object defines a document’s “top level”.
A document’s top level SHOULD contain a representation of the resource or collection of resources primarily targeted by a request (i.e. the “primary resource(s)”).
The primary resource(s) MUST be keyed by their resource type in plural form.
A document’s top level MAY also have the following members:
"meta": meta-information about a resource, such as pagination."linked": a collection of resource objects, grouped by type, that are linked to the primary resource(s) and/or each other (i.e. “linked resource(s)”).
No other members should be present at the top level of a document.
Singular Resources
Documents that represent singular resources are wrapped inside an array and keyed by the plural form of the resource type:
{
"contents": [{
"ref": "demo:example-1"
// ... attributes of this content
}]
}
This simplifies processing, as you can know that documents will always be wrapped in arrays.
The document SHOULD contain a resource identifier.
Resource Collections
Documents that represent resource collections are also wrapped inside an array and keyed by the plural form of the resource type:
{
"contents": [{
"ref": "demo:example-1"
// ... attributes of this content
}, {
"ref": "demo:example-2"
// ... attributes of this content
}]
}
Each document in the array SHOULD contain a resource identifier.
Resource Identifiers
Each document SHOULD have a unique identifier for the underlying resource, scoped to its type.
This may be represented by either "owner" and ‘"name" keys and/or a "ref" key. "ref" MUST be
the concatenation of "owner" and ‘"name"’ separated by a literal :.
Both "owner" and "name" MUST be a string which MUST only
contain alphanumeric characters, dashes and underscores (see name type).
"ref" can be used with URL templates to fetch related resources, as described below.
Attributes
There are three reserved attribute names in JSON API:
refownername
Every other key in a document represents an attribute. An attribute’s value may be any JSON value.
{
"contents": [{
"ref": "demo:example-1",
"title": "Example 1"
}]
}
Additionally, "custom" is used for account specific attributes, preserving the top level document attribute
namespace for service core attributes. This ensures that any future additions of core attributes will not cause
unexpected backwards incompatibility.
Relationships
Relationships are expressed through keys ending in Ref or Refs (for singular or plural values) containing
ref value(s).
{
"contents": [{
"ref": "demo:example-1",
"title": "Example 1",
"parentRef": "demo:parent",
"categoryRefs": ["demo:genre-drama", "demo:genre-action"]
}]
}
To-One Relationships
A to-one relationship MAY be represented as a singular ref that corresponds to the ref of a related resource.
{
"contents": [{
"ref": "demo:example-1",
"title": "Example 1",
"parentRef": "demo:parent"
}]
}
To-Many Relationships
A to-many relationship MAY be represented as an array of refs that corresponds to the refs of related resources.
{
"contents": [{
"ref": "demo:example-1",
"title": "Example 1",
"categoryRefs": ["demo:genre-drama", "demo:genre-action"]
}]
}
Compound Documents
To save HTTP requests, it may be convenient to send related documents along with the requested documents.
Related documents MUST be included in a top level "linked" object, in
which they are grouped together in arrays according to their type.
{
"contents": [{
"ref": "demo:example-1",
"title": "Example 1"
}, {
"ref": "demo:example-2",
"title": "Example 2"
}, {
"ref": "demo:example-3",
"title": "Example 3"
}],
"linked": {
"categories": [{
"ref": "demo:genre-action",
"title": "Action"
}, {
"ref": "demo:genre-drama",
"title": "Drama"
}],
"parents": [{
"ref": "demo:parent",
"title": "Parent"
}]
}
}
This approach ensures that a single canonical representation of each document
is returned with each response, even when the same document is referenced
multiple times (in this example, the author of the three posts). Along these
lines, if a primary document is linked to another primary or related document,
it should not be duplicated within the "linked" object.
By always combining documents in this way, a client can consistently extract and wire up references.
Browse & Get (Read)
browse indicates a read request that does not request specific documents by ID.
GET /people
get indicates a read request where documents are requested by specific known ID(s). For example:
GET /people/owner:name
Filtering Lists
All browse requests may be filtered using the following filter types.
q
q filters perform case insensitive text based searches against the specific fields indexed for the given resource.
Note that q filters split text into tokens at word boundaries using hyphens, whitespace and punctuation as delimiters. This means
that q=foo (1 token) will match the following examples:
foofoo-barFoo barfoo!bar
But it will not match against these:
foo_barfooBar
When there are multiple tokens in the filter then results matching one or more of them are returned. For example, q=foo bar, q=foo!bar, or q=foo!-bar (2 tokens) will match with:
barfooFoo!barfoo bar
The filter value can be double quoted to ensure all tokens are included as a phrase. Punctuation etc is still ignored in both the filter and result. This means that q="foo bar", q="foo!bar" or q="foo!-bar" will match the following examples:
foo!barfoo Barthe foo bar
But it will not match against these:
foobarbar foofoo and barfooBar
Quoting the value will not affect the characters included in tokens. For example, q=foo, "foo!", foo!, !foo, or "!foo" will match with the following examples:
foofoo!barfoo bar
When the filter string includes special URL characters they must be encoded to prevent unexpected behaviour:
#should be encoded as%23&should be encoded as%26
with
with filters are applied using the query parameter withFieldName=matchCriteria and support the following
match criteria by default:
| Syntax | Match criteria | Example |
|---|---|---|
| value | exact match | withTitle=Game+of+Thrones |
| !value | doesn’t match ‘value’ | withType=!image |
| * | field exists, any value | withContentRef=* |
| !* | field doesn’t exist | withContentRef=!* |
OR is supported using double pipe, e.g. withType=video||image
AND is supported using multiple query parameters, e.g. withTags=Jack&withTags=Jill
Note that + values are treated as spaces, so if queries require their usage encode them to %2B for the request.
e.g. withEmail=pikselproduct+12auser@gmail.com should be withEmail=pikselproduct%2B12auser@gmail.com
Nested field types e.g. { GBP: 4.99, USD: 9.99 } (money type) use the following syntax:
| Syntax | Match criteria |
|---|---|
| key:value | exact match |
| key:!value | doesn’t match ‘value’ |
| key:* | key exists, any value |
| key:!* | key doesn’t exist |
If a filter supports prefixes the match criteria can be supplied with a wildcard ending
| Syntax | Match criteria | Example |
|---|---|---|
| value* | starts with ‘value’ | withTitle=Walking* |
| key:value* | starts with ‘value’ | withPrice=4* |
::: alert info
Note: Nested fields with a fixed set of values e.g. ratings do not support prefix filtering.
:::
If a filter supports ranges the match criteria can define the required range of values to filter by. Ranges
work on numeric and date/timestamp types and the range separator is /. Ranges also support nested types.
| Syntax | Match criteria | Example |
|---|---|---|
| A/B | between A and B (inclusive) | withTimestamp=2000-01-01T00:00:00.000Z/2100-01-01T00:00:00.000Z |
| /A | less than or equal to A | withTimestamp=/2100-01-01T00:00:00.000Z |
| A/ | greater than or equal to A | withTimestamp=2000-01-01T00:00:00.000Z/ |
| !A/B | not between A and B (exclusive) | withTimestamp=!2000-01-01T00:00:00.000Z/2100-01-01T00:00:00.000Z |
| !/A | greater than A | withTimestamp=!/2000-01-01T00:00:00.000Z |
| !A/ | less than A | withTimestamp=!2100-01-01T00:00:00.000Z/ |
Note that when using a range filter, fields with Non-existence set to low or high will treat unset values
as being low or high and include them in ‘less than’ and ‘greater than’ queries respectively.
The following table shows how non-existence on fields affects the inclusion of unset values in the result set:
| Filter | x | low | high |
|---|---|---|---|
| /A | x | ✓ | x |
| !/A | ✓ | x | ✓ |
| A | x | x | x |
| !A | ✓ | ✓ | ✓ |
| A/ | x | x | ✓ |
| !A/ | ✓ | ✓ | x |
| A/B | x | x | x |
| !A/B | ✓ | ✓ | ✓ |
Filtering Related Documents
Related resources can be filtered using with filters. This is done by using the relationship name and the filter
name separated by a dot .:
GET "/data/people?include=contents&contents.withType=movie"
nth degree relationships can also be filtered in the same way:
GET "/data/people?include=contents.assets&contents.withType=movie&contents.assets.withType=image"
Note: You can filter the parent of a relationship without explicitly including the parent relationship. I.e.
?include=contents is not required in the example above.
Localisation
browse and get requests can request returned resources be localised by specifying the lang query string parameter e.g. ?lang=en.
Multiple languages can be passed as comma separated values e.g. ?lang=de-AT,de.
Localisation only applies to fields with a matching localised field on the resource.
If the chosen language is present inside the localised map object of a localisable field, then the field itself will be populated with the chosen language value. If it is not present, the localised map object will be returned.
With filtering, each of the languages is checked for existence in the order supplied. The first one that exists is queried. If none of the languages have an entry in the localised map then the default value is checked for a match and returned if successful.
Examples
GET "/data/contents"
{
"contents": [{
"owner": "test",
"name": "got-s01-e01",
"title": "Winter is coming",
"localisedTitle": {
"it": "L'inverno sta arrivando",
"es": "El invierno está llegando"
}
}]
}
GET "/data/contents?lang=it"
{
"contents": [{
"owner": "test",
"name": "got-s01-e01",
"title": "L'inverno sta arrivando"
}]
}
GET "/data/contents?lang=fr"
{
"contents": [{
"owner": "test",
"name": "got-s01-e01",
"title": "Winter is coming",
"localisedTitle": {
"it": "L'inverno sta arrivando",
"es": "El invierno está llegando"
}
}]
}
Counting
Count accurancy depends on the underlying datastore technology used, check every service.
Using count=true as a request parameter on a browse request will return the count of resources that
match the specified filtering criteria. If resources=false is also specified, the response will not
include the resources themselves.
Using count=false will prevent a count from being returned.
Facet counts
Using count=field (where field is any countable field) will return the total count along with a faceted count
of the field. Faceted counts are only available for fields that have the countable property set to true. If the field requested
is not countable then the request will be treated as a 400 Bad Request.
The following request is an example of a faceted count of the type field of a contents resource.
GET /data/contents/data/contents?owner=test&count=type
The response includes a facetCount object in the meta section that includes an object with the facet data for the
specified field.
{
"meta": {
"facetCount": {
"type": {
"episode": 1,
"movie": 1,
"show": 1,
"station": 1
}
},
"totalCount": 4,
// ...
}
}
Paginating Lists
All browse responses that include resources (i.e. where resources is not false) are paginated as standard.
An endpoint MUST support pagination based upon the following request parameters:
continue- supports forwards only traversal of result sets. It can not be used withpageorstartAt- see continueperPage- the number of items per page, optional, defaults vary depending on the serviceresources- whether to include the resources in the response, used in conjunction withcount, defaults totrue
The following parameters for pagination based on offset skipping are now DEPRECATED in favour of forward only traversal of result set:
page- the page number (one-indexed), optional, defaults to1. It can not be used withstartAtorcontinuestartAt- represents an offset to skip documents in a request, it has a minimum value of1. It can not be used withpageorcontinue- see startAtcount- include the total count, optional - see Counting
A server MUST support the following meta response attributes if resources are included in the response:
continue- a value used to hint to the service what data to return next - see continueperPage- the number of items per page, defaults vary depending on the service
The following attributes are now DEPRECATED:
first- the first page link, if there are 1 or more matching resourceslast- the last page link, if there are 1 or more matching resources andcount=truein the requestprev- the previous page linknext- the next page linkpage- the page number, defaults to1(paginating withpage)startAt- the requested offset (only usingstartAtas well other parameters like prev, next, first and last will be provided based on this value) - see startAttotalCount- the total number of matching items, ifcountis in the request
The default and maximum page size MAY differ for a given endpoint, but it MUST have a value.
Limits
The maximum number of resources that can be requested over pages is 10000 records (100 pages / 100 perPage)
continue
When set to true, will cause the response meta to contain a continue value to allow requesting the next set of results, if available. meta.continue will be omitted when there are no more results beyond the current set. The value of continue (when not true) is only to provide a hint to the service as to what data to return next, it is not intended to be used other than when following meta.continue links.
Clients are expected to follow the meta.continue from the response in order to get further results.
If perPage is not provided pagination.pageSize.default will be used instead.
Note: first, next, prev and last are never included in a response with continue true.
Note: continue MAY be used with <intersect> queries if the service supports it.
Examples
The following is a request with continue based pagination.
GET /data/resource?continue=true&perPage=100
For the above request meta information MIGHT be
{
"meta": {
"perPage": 100,
"continue": "0084416f492f436e526c633351364e475a684f5749795a545174597a45774d7930305a5455774c5467344f4467744e47517a4d544d774e5751315a574d3050784e6a623235305a573530637a70305a584e304f6a526d59546c694d6d55304c574d784d444d744e4755314d4330344f4467344c54526b4d7a457a4d44566b4e57566a4e413d3d00007fffff9b"
},
"resources": [
...
]
}
If continue is provided in meta it means there is a next page of results to read. Continue is a hash pointing to the next chunk of data to read. If continue is not provided then you have reached the end of the dataset and there is no more data to read.
startAt
This feature will be removed in future versions. If you are using it please switch to continue based pagination instead.
The minimum value for startAt is 1 with a maximum limit based on (pageSize.max * pages.max) - perPage. This limit
is required in order to avoid issues with slow performance with deep paging.
If perPage is not provided pagination.pageSize.default will be used instead.
For example the request /data/resource/?startAt=10 will skip the first 10 documents and return the number of
documents defined by the perPage default
Examples
The following request is an example of pagination with startAt. It MUST skip the first 10 documents and return the documents defined by the default perPage.
GET /data/resource?startAt=10
For the above request meta information MUST be
{
"meta": {
"startAt": 10,
"perPage": 10, // default value
"first": "/data/resource?startAt=1&perPage=10",
"prev": "/data/resource?startAt=1&perPage=10",
"next": "/data/resource?startAt=20&perPage=10"
},
"resources": [
...
]
}
startAt can be used alongside with perPage as well. In this case it will skip the first 5 documents and provide the following 100
GET /data/resource?startAt=5&perPage=100
And meta MUST be:
{
"meta": {
"startAt": 5,
"perPage": 100,
"first": "/data/resource?startAt=1&perPage=100",
"prev": "/data/resource?startAt=1&perPage=100",
"next": "/data/resource?startAt=105&perPage=100"
},
"resources": [
...
]
}
Get with multiple ids
If multiple ids are requested in a get, the response will be successful if one or more ids are found and
contain the list of found resources only. If no ids are not found, a 404 Not Found response
should be returned. Clients MUST interpret those errors in accordance with HTTP semantics.
Inclusion of Related Documents
All browse requests MUST support inclusion of direct and indirect related documents.
Note: Retrieving direct relationship using the include query parameter is now limited to retrieve 500 resources. Related resources retrieved as part of the relationship are sliced according to the limit established. It’s up to the client making the request to retrieve the remaining related items based on this meta section.
get requests with inclusion of direct or indirect related documents are not supported (use browse with withRef filter instead).
A server MAY choose to support returning compound documents that include both primary and related documents.
An endpoint MAY return documents related to the primary document(s) by default.
An endpoint MAY also support custom inclusion of related documents based
upon an include request parameter. This parameter should specify the path to
one or more documents relative to the primary document. If this parameter is
used, ONLY the requested related documents should be returned alongside the
primary document(s).
For instance, comments could be requested with a post:
GET /posts?include=comments
In order to request documents related to other documents, the dot-separated path of each document should be specified:
GET /posts?include=comments.author
Note: a request for comments.author should not automatically also include
comments in the response (although comments will obviously need to be queried in order to fulfil the request for their authors).
Multiple related documents could be requested in a comma-separated list:
GET /posts?include=author,comments,comments.author
Inclusion and meta links
Response MUST include the list of requests that were made in order to retrieve related documents in the meta section.
Examples
GET /data/contents?owner=test&include=offers
In this case, offers is directly linking contents and the request is including an indirect relationship. You will see the continue in the meta links in case there is more than one page of results:
"meta": { "perPage": 100, "page": 1, "linked": { "offers": [ { "perPage": 100, "continue": "0084416f492f436e526c633351364e475a684f5749795a545174597a45774d7930305a5455774c5467344f4467744e47517a4d544d774e5751315a574d3050784e6a623235305a573530637a70305a584e304f6a526d59546c694d6d55304c574d784d444d744e4755314d4330344f4467344c54526b4d7a457a4d44566b4e57566a4e413d3d00007fffff9b", "request": "/data/offers?continue=true&withContentRefs=test:content-1||test:content-2" } ] } }, contents: [{ "owner": "test", "name": "content-1" "ref": "test:content-1" }, { "owner": "test", "name": "content-2" "ref": "test:content-2" }], linked: { offers: [ ... ] }
In case of a request including a direct relationship such as browsing for a primary resource linking a related one via a ref field, you will also get the list of requests made in the meta.linked section, but this will not have to be paginated because all direct references will be looked up (500 items limitation):
GET /data/offers?owner=test&include=contents
"meta": { "perPage": 100, "page": 1, "linked": { "contents": [ { "request": "/data/contents/test:content-1,test:content-2" } ] } }, offers: [{ "owner": "test", "name": "offer-1" "ref": "test:offer-1", "contentRef": "test:content-1" }, { "owner": "test", "name": "offer-2" "ref": "test:offer-2", "contentRef": "test:content-2" }], linked: { contents: [ ... ] }
Inclusion with Intersect
Some relationships support the returned primary resources being intersected with the available secondary (related) resources. Using an <intersect> query causes the primary resources returned to be restricted to those which have at least one secondary resource matching the query (filter and sorting applicable).
The relationships supporting intersect are highlighted in the Service API documentation with the following message:
Intersectable: supports intersect criteria in the request
For instance, in the case of Metadata Service, leveraging the intersect support between Contents and Offers:
GET /contents?include=offers<intersect>
The browse API remains the same as with a standard include with the following exceptions:
- facet counting is not supported when an intersect include is applied
continuepagination MAY be supported when an intersect is applied if the service supports it- when requesting filters/fields/sort etc to apply the relationship the query parameters do not include the <intersect> part of the relationship. (e.g.
/contents?include=offers<intersect>&offers.withName=*&offers.fields=ref&offers.sort=ref)
Example
Without applying intersect, content items with no linked offer are returned:
GET /contents?fields=ref&offers.fields=ref,contentRefs&count=true&perPage=3&include=offers
{
"meta": {
"totalCount": 11,
...
},
"contents": [
{ "ref": "example:content-no-offer" },
{ "ref": "example:episode1" },
{ "ref": "example:episode2" }
],
"linked": {
"offers": [
{
"ref": "example:offer-2",
"contentRefs": [ "example:episode1" ]
},
{
"ref": "example:offer-3",
"contentRefs": [ "example:episode2" ]
}
]
}
}
When applying intersect, content items without linked offers are not returned:
GET /contents?fields=ref&offers.fields=ref,contentRefs&count=true&perPage=3&include=offers<intersect>
{
"meta": {
"totalCount": 8,
...
},
"contents": [
{ "ref": "example:episode1" },
{ "ref": "example:episode2" },
{ "ref": "example:movie2" }
],
"linked": {
"offers": [
{
"ref": "example:offer-2",
"contentRefs": [ "example:episode1" ]
},
{
"ref": "example:offer-3",
"contentRefs": [ "example:episode2" ]
},
{
"ref": "example:offer-6",
"contentRefs": [ "example:movie2", "example:movie3", "example:movie4" ]
}
]
}
}
Limited Fieldsets
A server MAY choose to support requests to return only specific fields for documents.
An endpoint MAY support requests that specify fields for the primary document
type with a fields parameter.
GET /people?fields=id,name,age
An endpoint MAY support requests that specify fields for any document type
with a RELATIONSHIP_NAME.fields parameter.
GET /posts?include=author&fields=id,title&author.fields=id,name
An endpoint SHOULD return a default set of fields for a document if no fields
have been specified for its type, or if the endpoint does not support use of
either fields or RELATIONSHIP_NAME.fields.
Sorting
A server MAY choose to support requests to sort documents according to one or more criteria.
An endpoint MAY support requests to sort the primary document type with a
sort parameter.
GET /people?sort=age
An endpoint MAY support multiple sort criteria by allowing comma-separated
fields as the value for sort. Sort criteria should be applied in the order
specified.
GET /people?sort=age,name
The default sort order SHOULD be ascending. A - prefix on any sort field
specifies a descending sort order.
GET /contents?sort=-created,title
The above example should return the newest contents first. Any contents created on the same date will then be sorted by their title in ascending alphabetical order.
An endpoint MAY support requests to sort any document type with a
RELATIONSHIP_NAME.sort parameter.
GET /contents?include=credit&sort=-created,title&credit.sort=name
If no sort order is specified, or if the endpoint does not support use of either
sort or RELATIONSHIP_NAME.sort, then the endpoint SHOULD return documents
sorted with a repeatable algorithm. In other words, documents SHOULD always
be returned in the same order, even if the sort criteria aren’t specified.
And endpoint SHOULD return an error when
- sort value is empty
- sort by a field that does not exist
- sort by a not sortable or prohibited field
- sort by the same field multiple times
- sort keyword is present more than one time
Store (Write)
Request
A JSON API document is stored by making a POST request to the URL that
represents a collection of documents that the supplied document should belong to.
While this method is preferred, you can always use anything that’s valid with
RFC 2616, as long as it’s compliant. For example, PUT can be used to create
documents if you wish.
In general, this is a collection scoped to the type of document.
The request MUST contain a Content-Type header whose value is
application/vnd.piksel+json. It MUST also include application/vnd.piksel+json
as the only or highest quality factor.
Its root key MUST be the same as the root key provided in the
server’s response to GET request for the collection.
For example, assuming the following request for the collection of assets:
GET /assets
HTTP/1.1 200 OK
Content-Type: application/vnd.piksel+json
{
"assets": [{
"ref": "demo:example-1",
"title": "Sticks",
"src": "http://example.com/images/sticks.png"
}]
}
You could store a photo by POSTing to the same URL:
POST /assets
Content-Type: application/vnd.piksel+json
Accept: application/vnd.piksel+json
{
"assets": [{
"title": "Sticks",
"src": "http://example.com/images/sticks.png"
}]
}
You could update the photo by PUTing to the id based URL:
PUT /assets/demo:example-1
Content-Type: application/vnd.piksel+json
Accept: application/vnd.piksel+json
{
"assets": [{
"ref": "demo:example-1",
"title": "Sticks",
"src": "http://example.com/images/sticks.png"
}]
}
Note: If the optional ref, owner or name supplied in the document differs from the URI ref
then the request should be treated as a 400 Bad Request.
Response
A server MUST respond to a successful store request with 200 OK.
Example:
HTTP/1.1 200 Ok
Content-Type: application/vnd.piksel+json
{
"assets": [{
"ref": "demo:example-1",
"title": "Sticks",
"src": "http://example.com/images/sticks.png"
}]
}
The body of the response MUST be a valid JSON API response, as if a
GET request was made to the same URL.
Whenever a server returns a 200 OK response it MAY include
other documents in the JSON document. The semantics of these documents
are the same as when additional documents are included in fetch responses.
Other Responses
Servers MAY use other HTTP error codes to represent errors. Clients MUST interpret those errors in accordance with HTTP semantics.
Delete (Write)
Request
A JSON API document is deleted by making a DELETE request to the
document’s URL.
DELETE /assets/test:1
Multiple documents can be deleted by comma separating the documents
DELETE /assets/test:1,test:2
Response
204 No Content
If a server returns a 204 No Content in response to a DELETE request, it means that the deletion was successful.
Some resource restrictions (e.g. unmodifiable) may cause DELETE requests to return a 204 No Content without deleting the resource.
This behaviour may change in a future update.
200 Ok
Whenever a server returns a 200 OK response it MAY include
other documents in the JSON document. The semantics of these documents
are the same as when additional documents are included in fetch responses.
Other Responses
Servers MAY use other HTTP error codes to represent errors. Clients MUST interpret those errors in accordance with HTTP semantics.
Errors
When an error occurs, the response body should be application/json and have the following
attributes:
statusCode- the http status code, e.g.404error- the http status reason phrase, e.g.Not Foundmessage- [optional on 400] human readable description of the error reasonvalidation- [optional on 400] an object providing details of the validation failure
Note: message MUST NOT be used for error handling purposes - it is purely descriptive and subject to change.
Changes
History
2018-04-16 (v1.10)
- Corrected media type filter examples
2018-01-05 (v1.9)
- Updates documentation to reflect change from
201 Createdresponse to200 OK
2017-10-16 (v1.8)
- Changed count to return a
400 Bad Requeston requests for uncountable or non existant fields.
2017-09-28 (v1.7)
- Add details of intersect queries
2017-08-16 (v1.6)
- Added a note to indicate encoding requirements for “+”
2017-07-21 (v1.5)
- Add documentation on deleting multiple resources in a single request
2017-03-24 (v1.4)
- Added startAt usage and examples
2016-11-13 (v1.3)
- PATCH removed from the API
- Relationships changes and reviews
2016-11-08 (v1.2)
- Add relationship filtering section to spec
2016-10-11 (v1.1)
- update spec for new relate sort syntax
2014-11-07 (v1.0)
- First formal release